How the Platform Connects to Your Storage
CloudSoda’s architecture follows a simple principle: agents deploy where the data lives. Rather than pulling data to a central location for analysis, the platform pushes lightweight agents to the edge of your storage infrastructure. As a result, metadata collection stays fast and data transfers remain local to the network where they matter most.
The Four Layers
At its core, CloudSoda’s architecture has four layers: the controller, agents, accessors and storage. Each layer has a specific role, and together they give the platform its flexibility across any combination of on-premises and cloud storage.
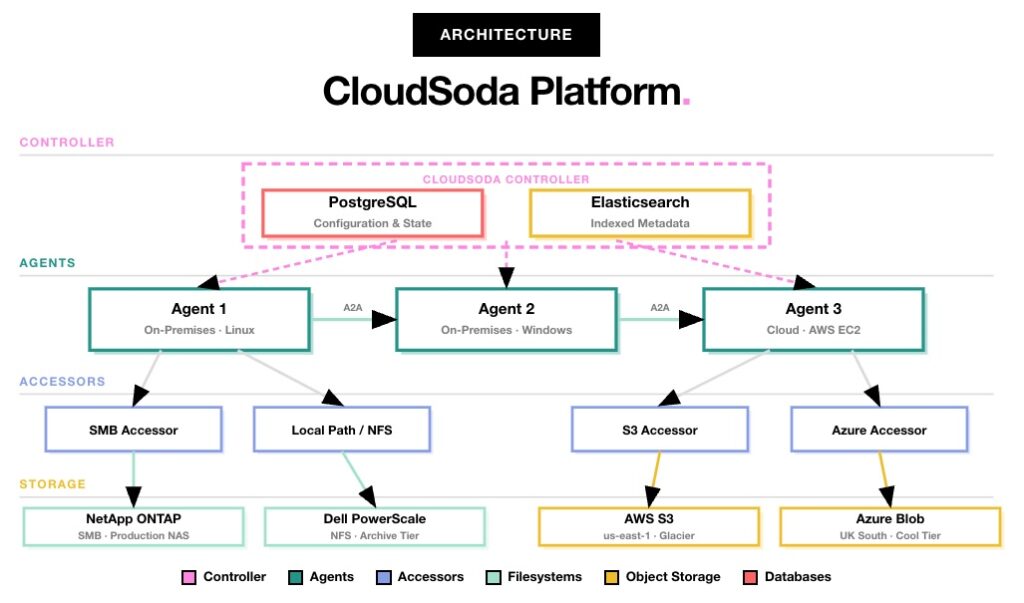
Controller
The controller serves as the central hub of the platform, running two core databases. PostgreSQL stores all configuration state — including jobs, policies, users, roles and storage definitions. Meanwhile, Elasticsearch holds the indexed metadata from every scan, making billions of file records searchable in seconds.
In addition, the controller hosts the web UI, the GraphQL API and the job engine that dispatches work to agents. For environments under 250 million files, it runs as a single instance. However, for larger estates, you can deploy it as a cluster with separate Elasticsearch nodes to handle the additional indexing load.
Agents
Agents act as lightweight services that you deploy near your storage systems. Specifically, they handle scanning, indexing and data transfer operations. Each agent registers with the controller over HTTPS and receives job assignments automatically.
You can run agents on Linux, Windows or as cloud instances on AWS, Azure or GCP. In other words, you deploy them wherever your storage is — in your London data centre, in a Los Angeles production facility, or on an EC2 instance next to your S3 buckets. Furthermore, multiple agents can work on a single job in parallel through agent clustering, which distributes the workload for maximum throughput.
Accessors
Accessors form the protocol-specific connection layer between agents and storage. Essentially, they abstract away the differences between storage types so the rest of the platform does not need to care whether it talks to a NAS filesystem or a cloud bucket.
Currently, CloudSoda supports SMB accessors for Windows shares and CIFS, local path accessors for NFS mounts, S3 accessors for AWS and S3-compatible storage, and Azure accessors for Blob storage. Additionally, the platform integrates directly with Dell PowerScale via its API, enabling snapshot-based delta scanning without NFS or SMB mounts.
Storage
Storage represents everything CloudSoda connects to. On the filesystem side, this includes NetApp ONTAP and Dell PowerScale. On the cloud side, it covers AWS S3, Azure Blob, Google Cloud Storage, Wasabi and Backblaze B2. Importantly, you can manage any combination of these from a single CloudSoda deployment.
Hub and Spoke Deployment
In practice, most CloudSoda deployments follow a hub and spoke topology. The controller sits centrally — either on-premises or in the cloud — while agents fan out across each storage location. For example, an agent in your London office scans and transfers from local NAS. At the same time, an agent on AWS handles S3 and Glacier operations, and a separate agent in your Los Angeles facility connects to production storage there.
All agents communicate back to the controller over HTTPS. Consequently, metadata flows inward for indexing and analytics, while transfer instructions flow outward for data movement. Because agent-to-agent transfers happen directly between locations — without routing data through the controller — both transfer speeds and latency stay optimal.
Metadata-Only Architecture
Crucially, CloudSoda never copies or moves your actual file data during scanning. Instead, the platform collects and indexes only metadata. As a result, your data stays on your storage systems and never leaves your control. This approach makes CloudSoda safe for regulated environments and removes any concerns about data residency during the intelligence-gathering phase.