A Distributed Architecture for Multi-Site Storage Management
Enterprise storage rarely lives in one place. Most organisations spread unstructured data across multiple data centres, cloud regions and geographic locations. As a result, traditional storage management tools — designed for single-site environments — simply cannot keep up.
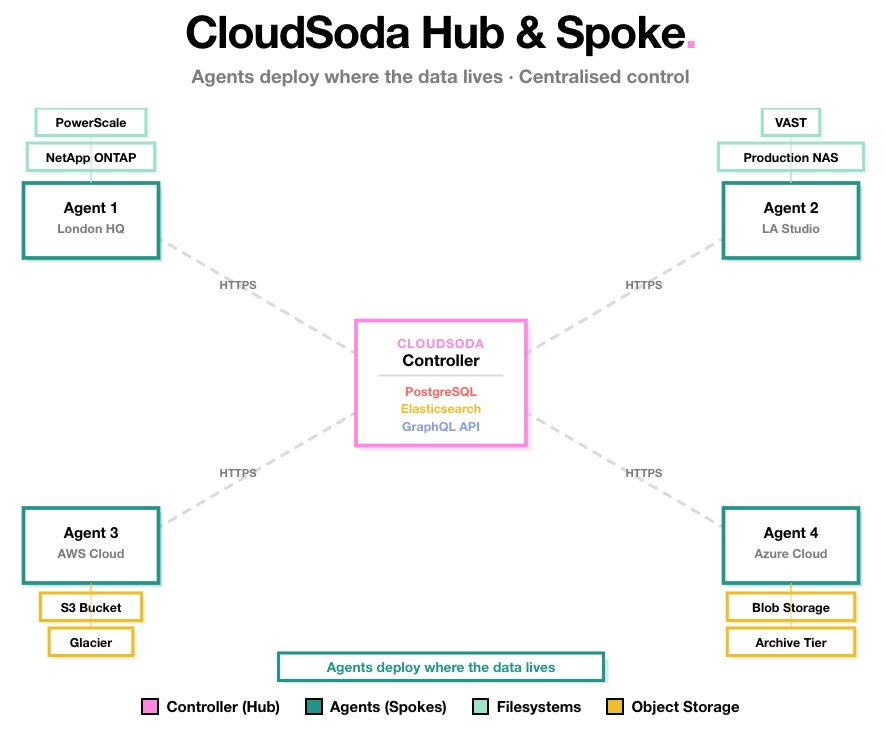
CloudSoda solves this with a hub and spoke topology. A central controller acts as the hub, while lightweight agents deploy as spokes near each storage location. Consequently, scanning stays fast, transfers stay local and you manage everything from a single interface — regardless of how many sites, vendors or cloud providers you operate.
🏗 How the Hub and Spoke Model Works
The concept is straightforward. At the centre sits the CloudSoda controller — the hub — which hosts the web UI, the job engine, the GraphQL API, PostgreSQL for configuration and Elasticsearch for indexed metadata. This is where you configure storage, create jobs, run analytics and manage users.
Around the controller, you deploy agents — the spokes — near each storage location in your environment. Each agent registers with the controller over HTTPS, receives job assignments and executes them locally. Importantly, agents handle all scanning and data transfer operations at the edge, close to the storage they manage. Only metadata flows back to the controller for indexing.
Because of this design, CloudSoda avoids the bottleneck of funnelling all data through a single central point. Instead, the platform distributes the work to where it makes the most impact.
🌍 Agents Deploy Where the Data Lives
This principle drives every CloudSoda deployment. Rather than requiring storage to connect back to a centralised scanning engine, you place agents alongside the storage systems they serve.
For example, a typical media and entertainment deployment might look like this:
London headquarters. An agent runs on a Linux server with direct access to NetApp ONTAP and Dell PowerScale filers via SMB and NFS. It handles daily metadata scans and local transfers between on-premises storage tiers.
Los Angeles production facility. A second agent connects to production NAS holding raw camera footage and VFX renders. It scans locally and can transfer directly to the London agent for cross-site data movement.
AWS us-east-1. A third agent runs on an EC2 instance next to the organisation’s S3 buckets and Glacier archives. It handles cloud scanning and serves as the destination agent for on-premises-to-cloud migrations.
Azure UK South. A fourth agent connects to Azure Blob storage for disaster recovery and cool-tier archiving. It receives data from on-premises agents during automated tiering workflows.
All four agents report back to a single CloudSoda controller. As a result, the administrator sees a unified view of every storage system across all four locations — without needing to log into separate vendor dashboards or cloud consoles.
⚡ Agent-to-Agent Communication
One of the most powerful aspects of the hub and spoke model is how agents communicate with each other during transfers. When you create a job that moves data from London to AWS, the source agent in London reads the data from local NAS and streams it directly to the destination agent on EC2. Crucially, this data never routes through the controller.
Because transfers flow directly between agents, CloudSoda achieves the lowest possible latency for each job. The controller only handles coordination — dispatching the job, tracking progress and recording results. Meanwhile, the actual data takes the shortest path between source and destination.
Furthermore, agents communicate over encrypted HTTPS, so cross-site transfers work across any network topology. Whether your agents sit on the same LAN, across a WAN, or span public internet connections between cloud regions, the protocol stays the same.
🧩 Agent Clustering for Maximum Throughput
In addition to the basic hub and spoke model, CloudSoda supports agent clustering. This means a single transfer job can leverage multiple agents working in parallel on the same workload.
For instance, if you deploy four agents with access to both the source and destination storage, CloudSoda distributes the file list across all four. Each agent handles a portion of the transfer concurrently. As a result, deploying four agents instead of one can reduce transfer times by up to 60%.
This clustering capability also provides resilience. If one agent fails mid-transfer, the remaining agents continue the job without starting over. CloudSoda reassigns the failed agent’s work automatically, so a hardware issue on one machine does not derail the entire migration.
🔒 Metadata-Only at the Hub
A common concern with centralised management platforms is data security. Specifically, organisations want to know whether their actual file data passes through the central controller.
With CloudSoda, the answer is no. The controller only receives metadata — file names, paths, sizes, timestamps, permissions and ownership attributes. It never sees, stores or processes file contents. Your actual data stays on your storage systems at all times.
As a result, the hub and spoke model works safely in regulated environments with strict data residency requirements. The controller can even run in a different region or country from the storage it manages, because only metadata crosses that boundary.
📐 Flexible Controller Deployment
The controller itself can run wherever makes sense for your organisation. You have two main options.
Single-instance deployment. For environments with up to 250 million files, a single server hosts PostgreSQL, Elasticsearch and the CloudSoda application stack. This is the fastest way to get started and suits most mid-scale deployments.
Cluster deployment. For larger environments — up to 2 billion files — you separate the controller and Elasticsearch onto dedicated nodes. Adding more Elasticsearch nodes scales indexing performance linearly. For example, three Elasticsearch nodes handle up to 1 billion files, while five nodes support up to 2 billion.
In both cases, you deploy the controller on Ubuntu 22.04 LTS or RHEL 9. Cloud-hosted controllers on AWS (using m6i.4xlarge instances with GP3 storage) work just as well as on-premises deployments. The choice depends on where your team prefers to manage infrastructure.
🔄 Real-World Deployment Patterns
Because the hub and spoke model is flexible, organisations adapt it to their specific infrastructure. Here are three common patterns.
Hybrid on-premises and cloud. The controller runs on-premises alongside the majority of storage. Cloud agents handle S3 and Azure scanning plus migration jobs. This is the most common pattern for organisations beginning their cloud journey.
Cloud-first with on-premises spokes. The controller runs on AWS or Azure, with on-premises agents connecting back over HTTPS. This suits organisations that have already centralised IT operations in the cloud but still maintain legacy NAS.
Multi-cloud with geographic distribution. The controller runs in one cloud region, with agents spread across AWS, Azure, GCS and on-premises locations globally. This pattern works well for multinational organisations managing storage across multiple countries and providers.
Regardless of the pattern, every deployment shares the same architecture. The controller provides centralised visibility and control. The agents provide distributed execution near the data. Together, they give you global reach with local performance.
🚀 Why Hub and Spoke Matters
Many storage management tools require you to centralise data before you can analyse or move it. This approach creates network bottlenecks, increases transfer times and raises data security concerns.
CloudSoda’s hub and spoke topology avoids all of this. By distributing agents to each storage location, the platform keeps operations local and fast. At the same time, the central controller ensures you maintain a single, unified view of your entire data estate.
For organisations managing petabytes of unstructured data across multiple vendors, geographies and cloud providers, this architecture is not just a convenience — it is a requirement for managing data at scale.
Deploy CloudSoda agents wherever your data lives and manage everything from one place. [See the hub and spoke architecture in a demo →]